
1. Quick Integration
1.1 Get an API Key
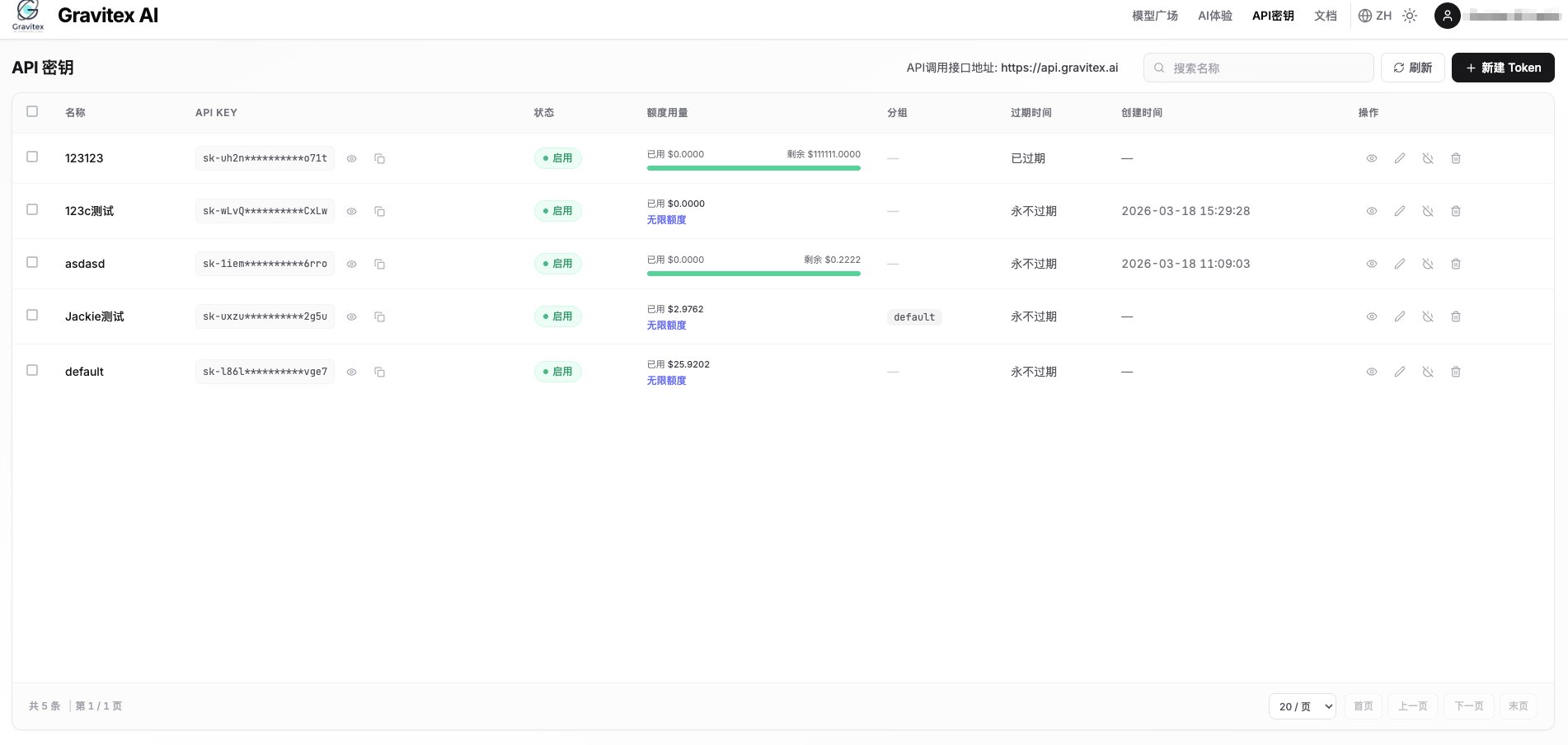
Visit the GravitexAI Console and create an API key: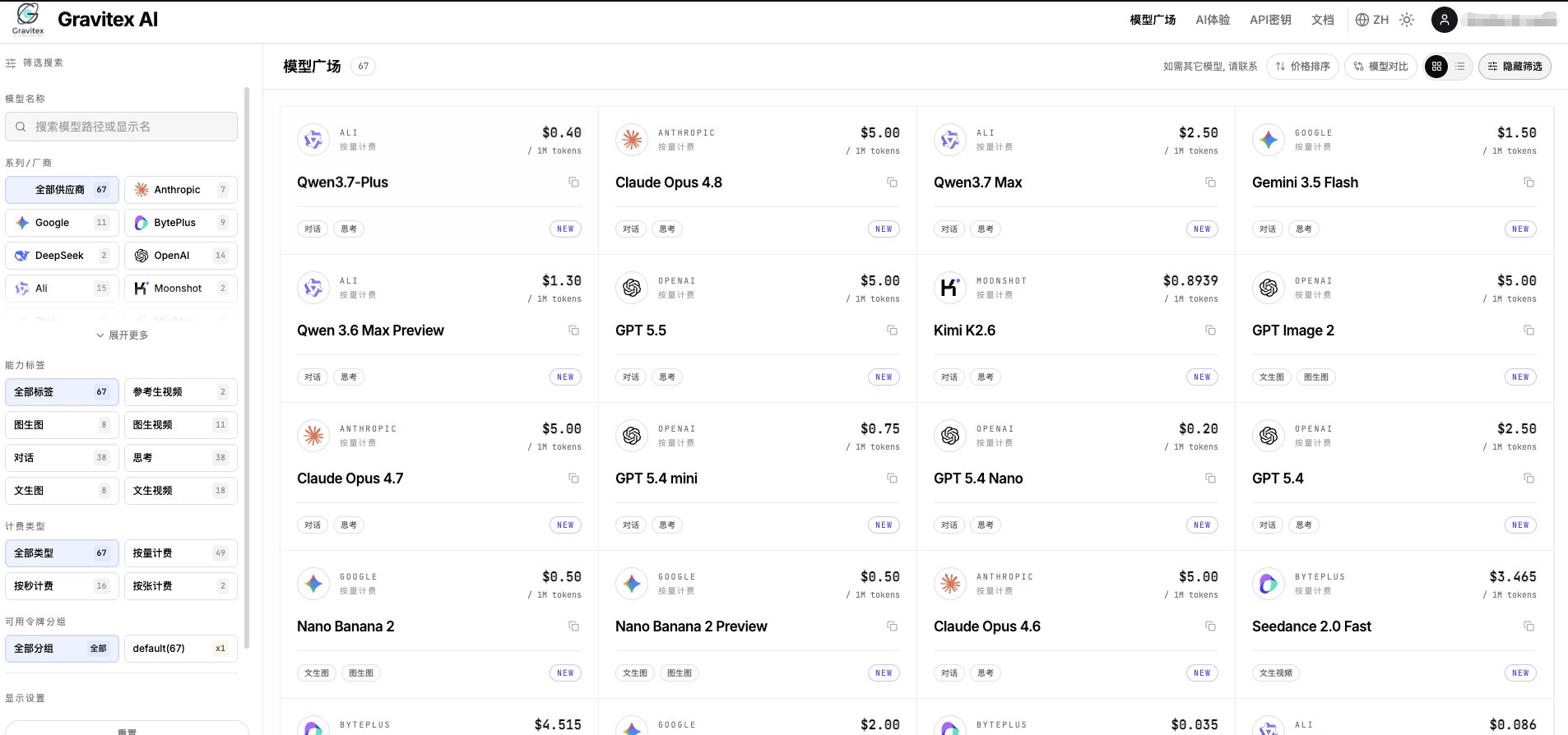
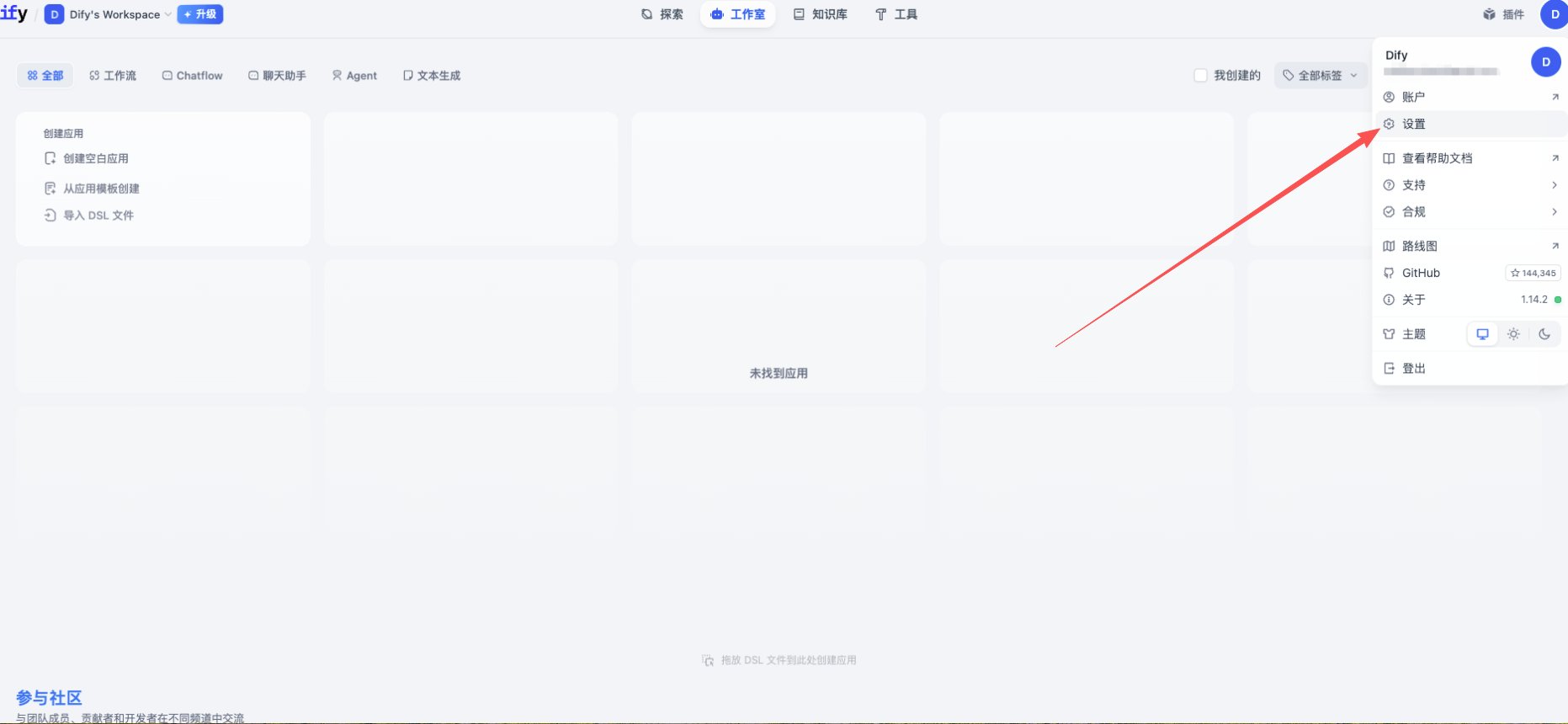
1.2 Open Dify Model Providers
- Log in to Dify, click your avatar (top-right) → Settings
- From the left menu, choose Model Provider
- Find the OpenAI-API-compatible plugin in the list and install it
OpenAI-API-compatible supports LLM / Embedding / TTS / STT endpoint types. GravitexAI is fully compatible — one plugin covers every model.
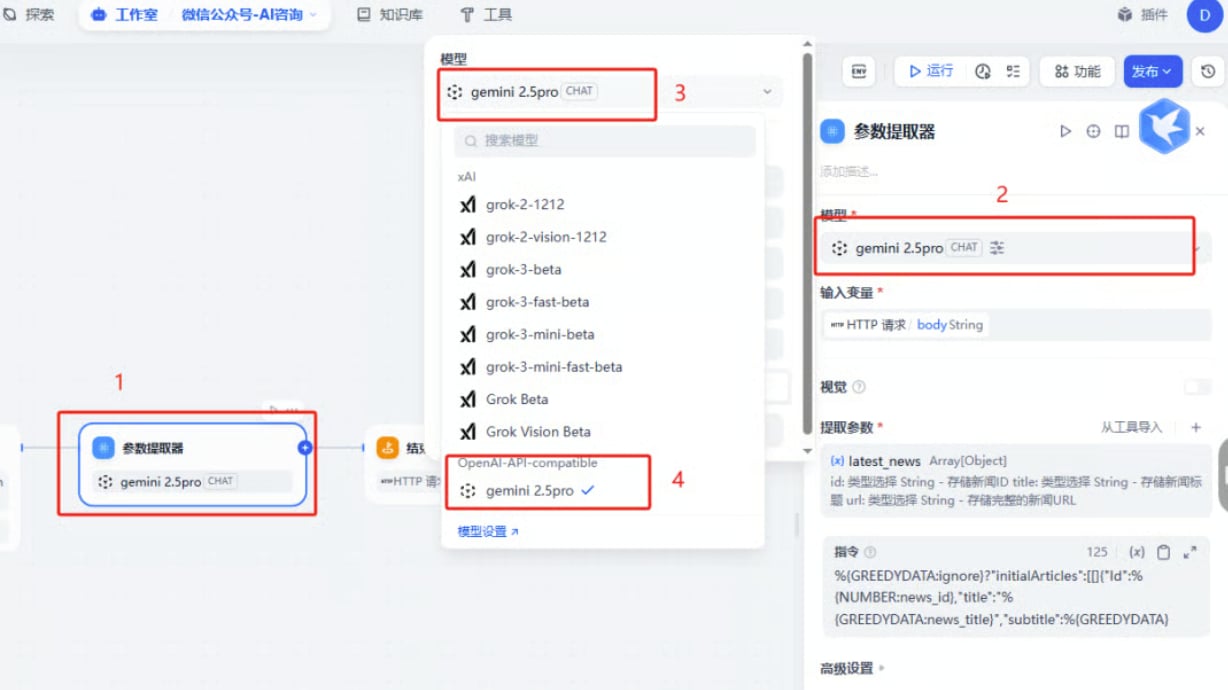
1.3 Add a Model
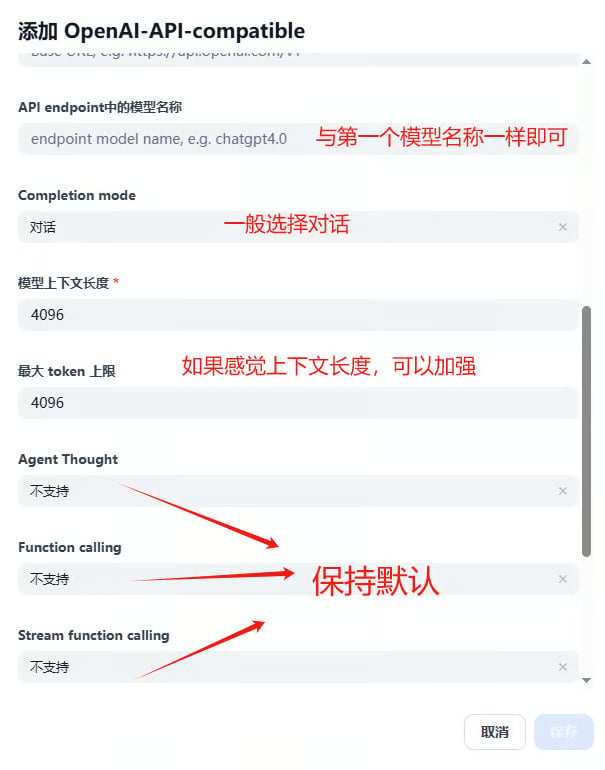
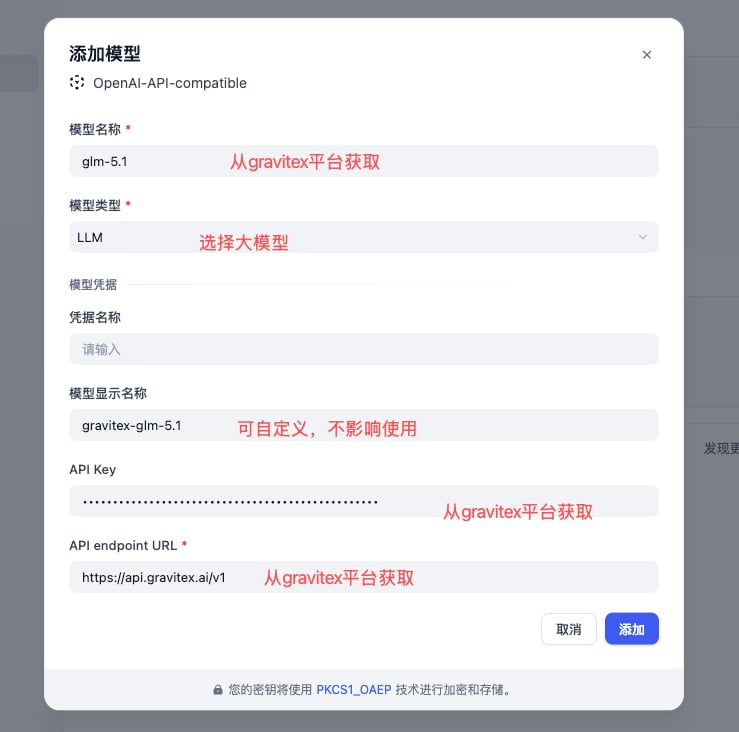
After installing the plugin, click Add Model and fill in the three core fields below: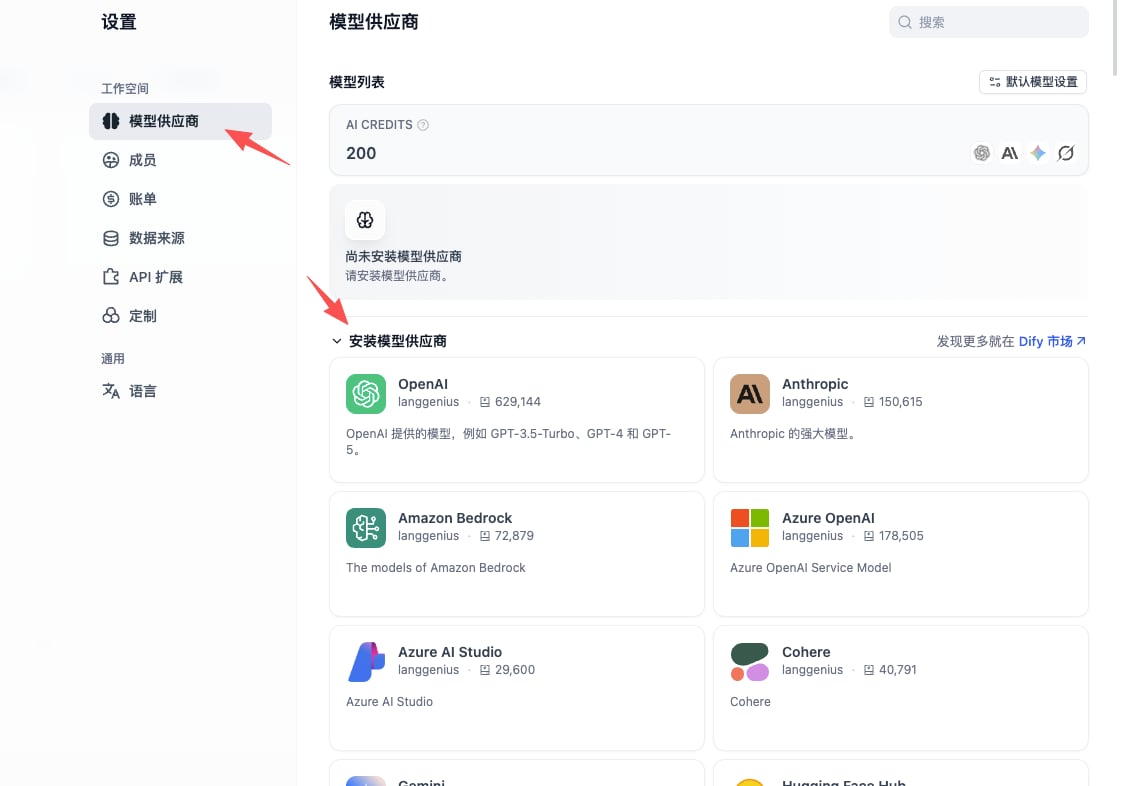
1.4 Context Length
Dify defaults tomax_context = 4096, which is far below most modern models. Override it based on the model you choose:
Full context specs live on the model catalog.
2. Core Features
2.1 Chat Assistant
The simplest app type — great for support bots, Q&A, and role-play:- Create app → choose Chat Assistant template
- Configure the system prompt:
- Pick
gpt-5.5orclaude-opus-4-7as the model - Suggested parameters:
temperature = 0.7,max_tokens = 2000
2.2 Workflow Application
Compose multi-step DAGs with branches, parallel paths, and loops: Node-by-node model suggestions:- Intent classification:
gemini-3.5-flash(high throughput, low latency) - KB retrieval / embedding:
text-embedding-3-largeorgemini-embedding-001 - Long-doc reasoning:
claude-opus-4-7(1M context, strong reasoning) - Code generation:
gpt-5.5orqwen3-coder-plus
2.3 Knowledge Base Q&A (RAG)
- Create a knowledge base → upload documents (PDF / Word / Markdown / TXT)
- Embedding model:
text-embedding-3-largerecommended - Chunking: auto-split by paragraph, ~500 tokens per chunk
- Reference the KB in the app
- Retrieval parameters:
- Top-K: 3–5
- Similarity threshold: 0.7
- Reranker: enabled (significantly improves relevance)
3. Application Templates
- Customer Support
- Document Analysis
- Coding Assistant
4. Advanced Features
4.1 Call Dify Apps via API
Each Dify app is exposed as an HTTP service that can be called from outside:4.2 Multimodal Input (Vision)
Vision-capable models (gpt-5.5, claude-opus-4-7, gemini-3.5-flash) accept image input:
4.3 Batch Processing
For large-scale workloads (CSV imports, bulk summarization, etc.):- Pick a fast/cheap model (
gemini-3.5-flash,gpt 5.4 mini) - Cap concurrency in your Dify workflow to avoid hitting rate limits all at once
- Enable result caching to avoid re-billing identical inputs
5. Model Selection
Full scenario-based model picks
Browse GravitexAI’s recommendations across writing, coding, fast response, long-context, image generation, and more.
Cost optimization: dev vs prod
GravitexAI provides platform-level automatic failover. If a provider is unavailable, traffic is routed to an equivalent model automatically — no manual fallback chain in Dify required.
6. Best Practices
6.1 Structured prompts
6.2 Workflow design
6.3 Observability
Track regularly:- ✅ User feedback (thumbs up/down)
- ⏱️ P95 latency
- 💰 Cost per call and daily/monthly usage curve
- ❌ Error rate and root cause distribution
6.4 Versioning
- Regularly export Dify app configs (JSON / YAML) as backups
- Roll out new versions via canary; keep at least N-1 for rollback
- Pin model versions in production to avoid surprise behavior changes
7. Troubleshooting
401 / invalid API key- Re-copy the API key from the GravitexAI Console
- Verify the account has balance
- Confirm baseURL is
https://api.gravitex.ai/v1(note the trailing/v1)
- Use the canonical model ID (e.g.
gpt-5.5, notGPT-5.5) - “Model Name” and “Model Name in API endpoint” must be identical
- Prefer Flash / Mini tier models
- Reduce
max_tokens - Turn on Dify response caching
Performance tuning template
8. Deployment Recommendations
Production Docker Compose (self-hosted Dify)
Security
- Store the API key in env vars or a secrets manager — never hardcode it inside Dify configs
- Terminate HTTPS in front of Dify (Nginx / Caddy / Traefik)
- Enable SSO / 2FA for the Dify admin console
- Keep base images and dependencies up to date
Health checks
9. Reconciliation & Insights
Once integrated, head back to the GravitexAI Console to see request volume, token consumption, cost breakdown, and per-model success rates: