
一、快速集成
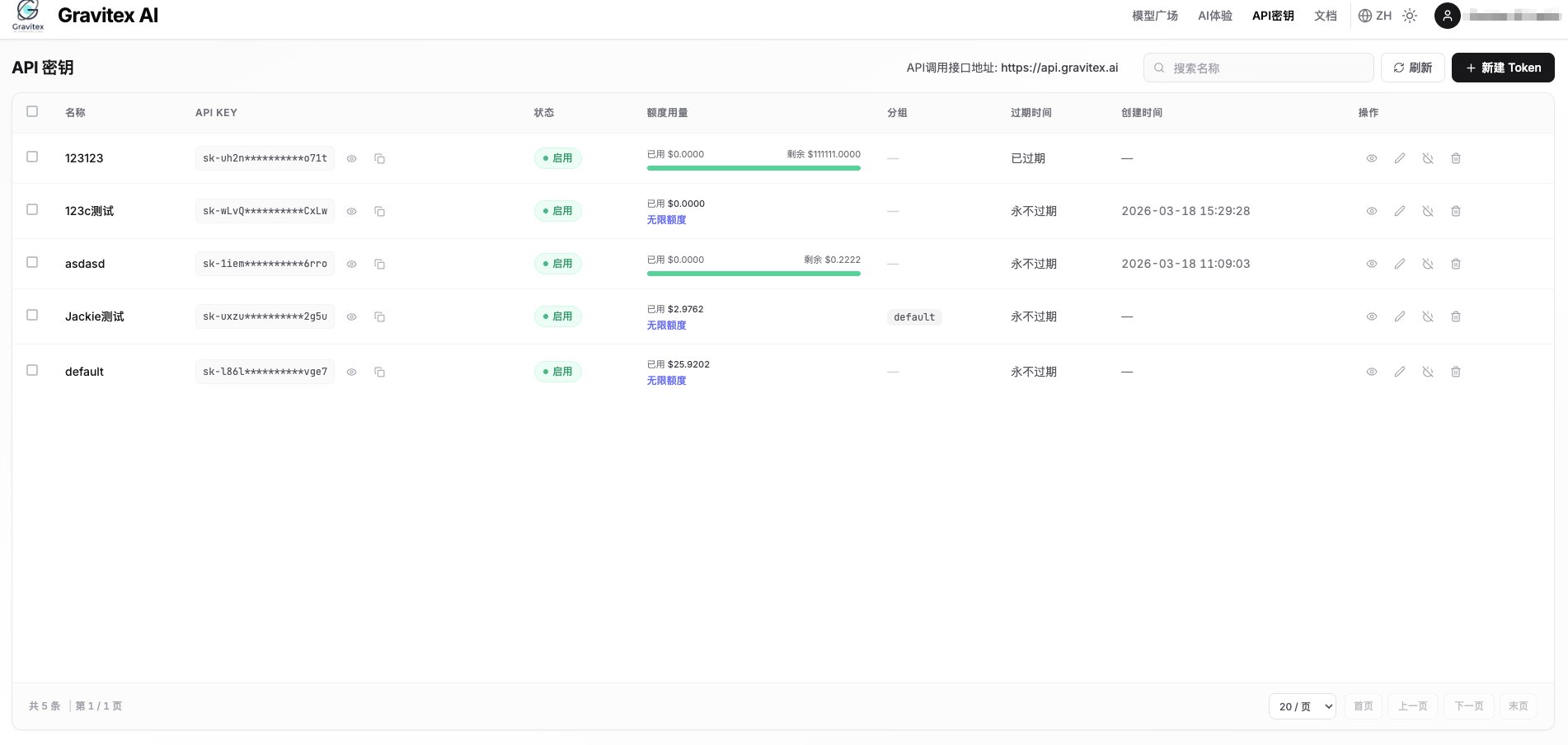
1. 获取 API 密钥
访问 GravitexAI 控制台 创建一个 API Key:
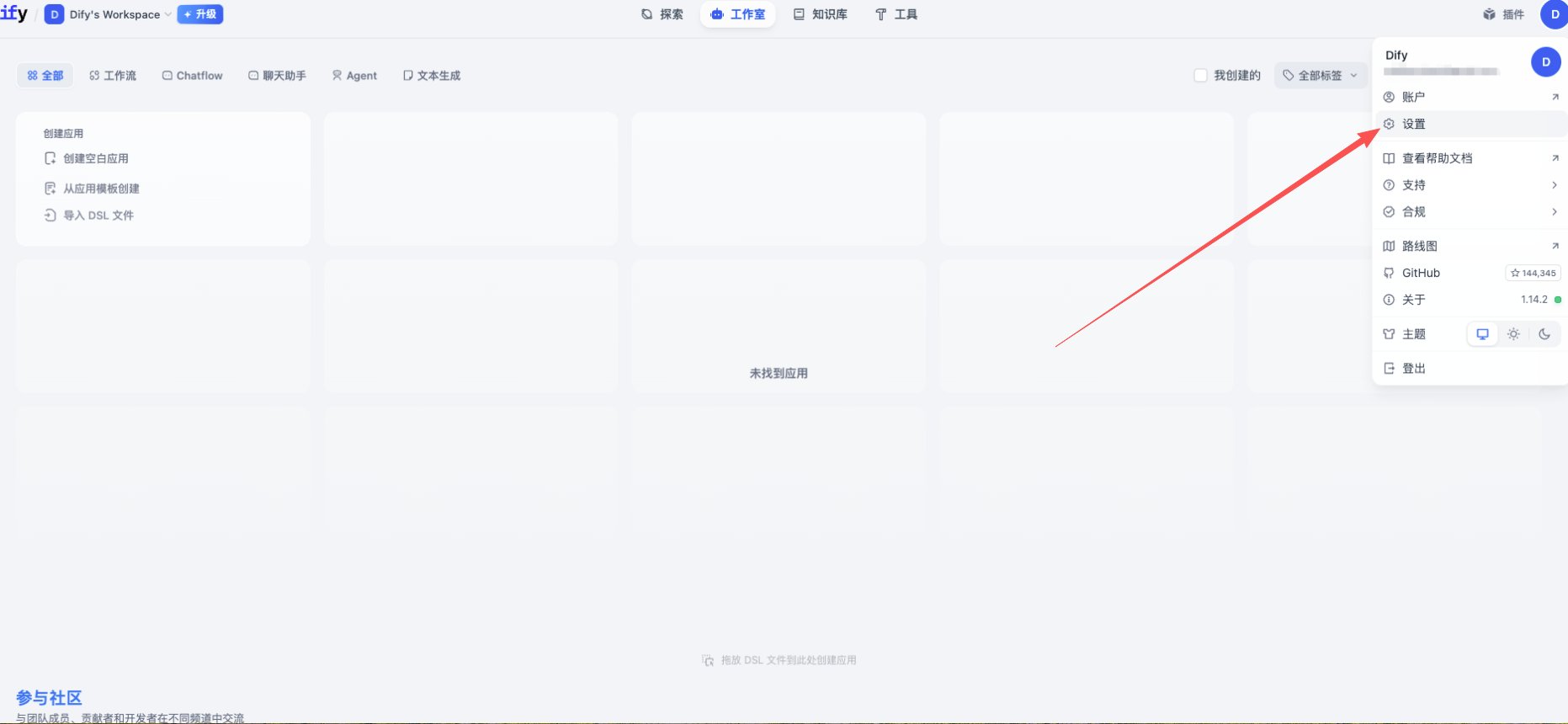
2. 进入 Dify 模型供应商设置
- 登录 Dify 平台,点击右上角用户名 → 设置
- 左侧菜单选择 模型供应商
- 在列表中找到 OpenAI-API-compatible 插件并点击安装
OpenAI-API-compatible 插件支持 Chat / Embedding / TTS / STT 等多种端点类型,GravitexAI 全部兼容,一个插件即可覆盖所有模型。
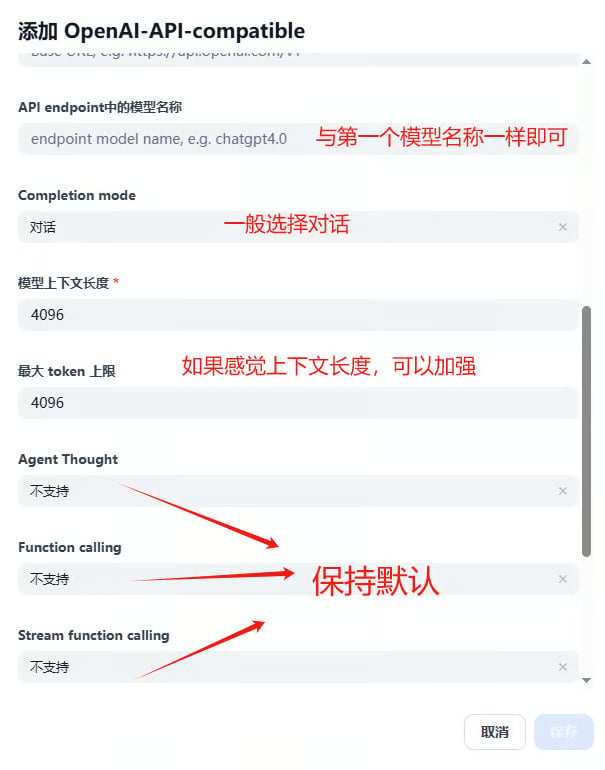
3. 添加模型配置
安装插件后,点击 增加模型,填入以下三个核心参数: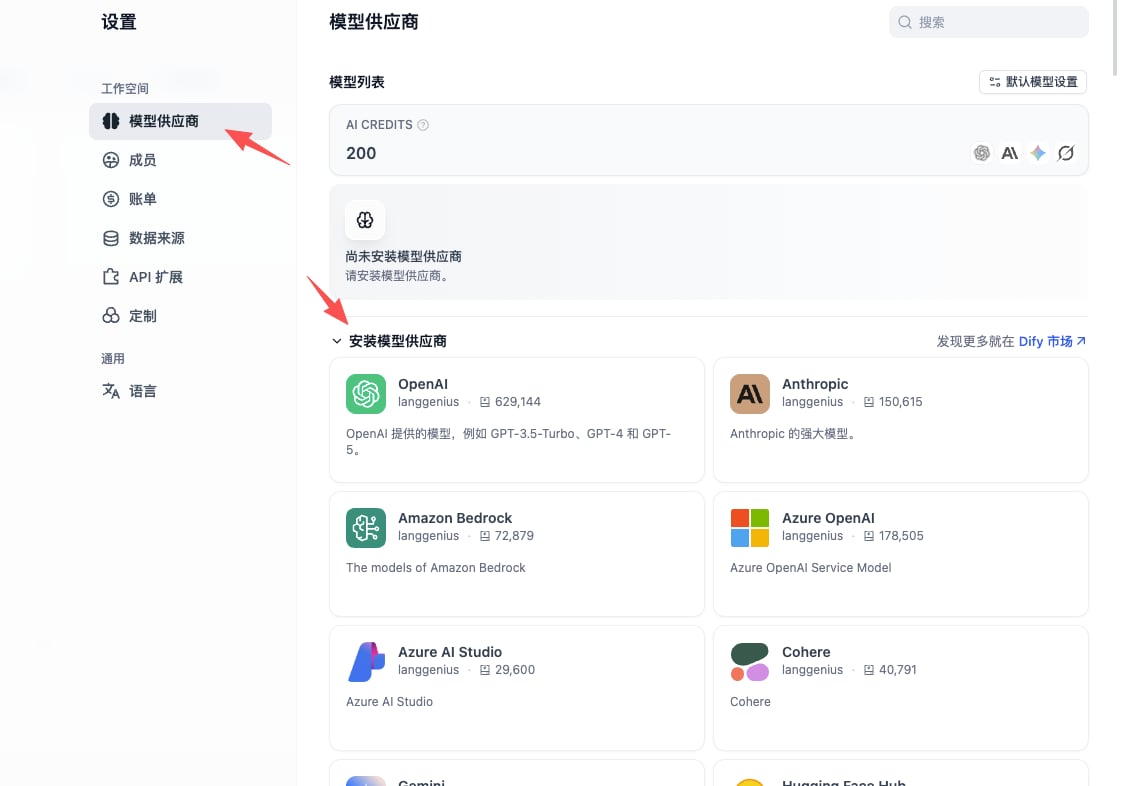
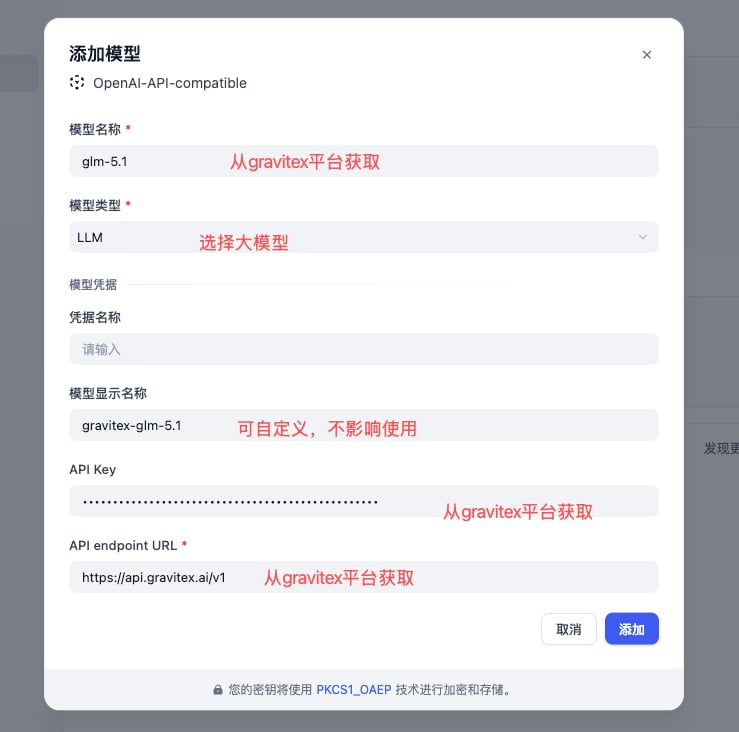
4. 配置上下文长度与参数
Dify 默认max_context = 4096,这对大多数现代模型来说远低于实际能力。请按实际模型设置:
完整模型上下文规格请参考 模型广场。
二、核心功能
1. 对话助手
最简单的应用类型,适合客服、知识问答、角色扮演等场景:- 创建应用 → 选择 对话助手 模板
- 配置系统提示词:
- 模型选择
gpt-5.5或claude-opus-4-7 - 推荐参数:
temperature = 0.7,max_tokens = 2000
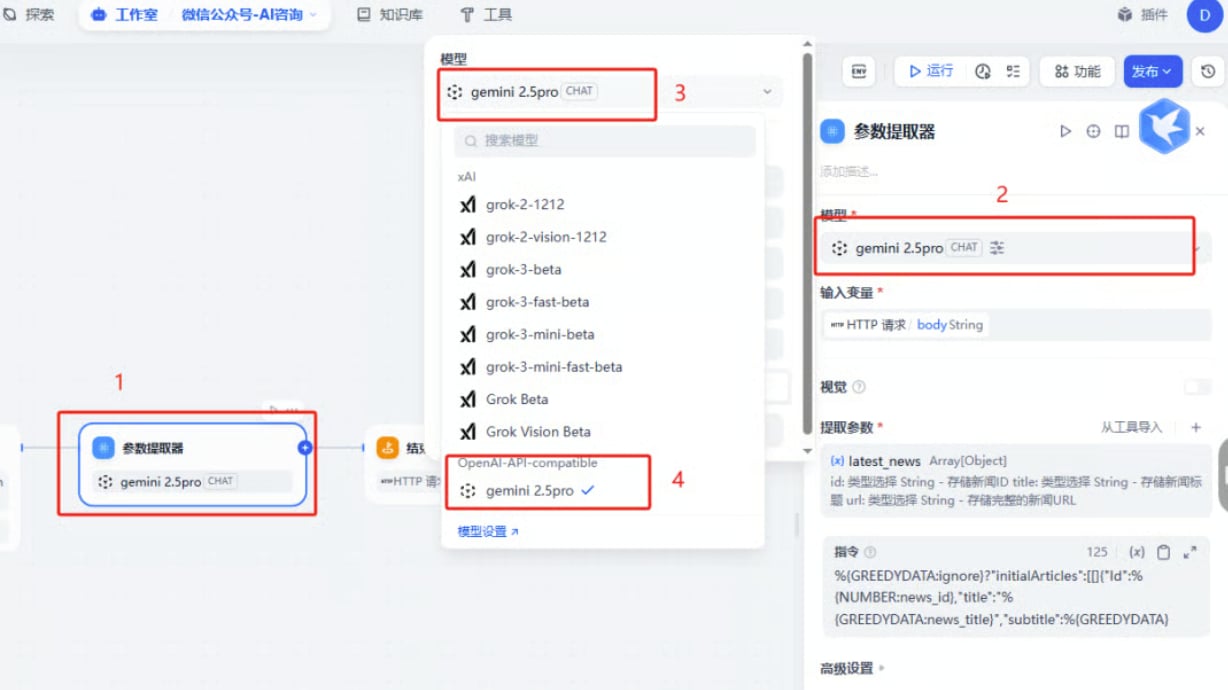
2. 工作流应用
将多个步骤编排成 DAG,支持条件分支、并行、循环: 典型节点选型建议:- 意图分类:
gemini-3.5-flash(高吞吐低延迟) - 知识库检索 / 嵌入:
text-embedding-3-large或gemini-embedding-001 - 长文复盘 / 推理:
claude-opus-4-7(1M 上下文,强推理) - 代码生成:
gpt-5.5或qwen3-coder-plus
3. 知识库问答(RAG)
- 创建知识库 → 上传文档(PDF / Word / Markdown / TXT 等)
- 选择嵌入模型:推荐
text-embedding-3-large(OpenAI) - 分段策略:按段落自动分块,平均 500 token / 段
- 在应用中引用知识库
- 配置检索参数:
- Top-K: 3-5
- 相似度阈值: 0.7
- 重排序:开启(显著提升召回相关性)
三、应用类型与配置示例
- 智能客服
- 文档分析
- 编程助手
四、高级功能
1. 通过 API 调用 Dify 应用
Dify 应用本身可作为 HTTP 服务被外部调用。下面以一个对话助手为例:2. 多模态(图片输入)
支持视觉理解的模型(gpt-5.5、claude-opus-4-7、gemini-3.5-flash)可以接收图片输入:
3. 批量处理
针对大规模数据集(CSV 导入、文档批量摘要等),建议:- 选用低成本快速模型(
gemini-3.5-flash、gpt 5.4 mini) - 设置 Dify 工作流的并发上限,避免一次性打满速率
- 启用结果缓存,避免重复内容重复调用
五、模型选择策略
完整场景化模型推荐
查看 GravitexAI 全场景模型推荐:文本创作、编程、快速响应、长文本、图像生成等。
成本优化:开发 vs 生产
GravitexAI 平台层面支持自动故障转移:某家供应商不可用时,平台会自动切到等价模型,无需在 Dify 侧做手动 fallback。
六、最佳实践
1. 结构化提示词
2. 工作流设计
3. 监控与优化
定期审视:- ✅ 用户满意度反馈(收集 thumbs up/down)
- ⏱️ P95 响应时间
- 💰 单次调用成本与日 / 月用量曲线
- ❌ 错误率与失败原因分布
4. 版本管理
- 定期导出 Dify 应用配置(JSON / YAML)备份
- 测试新版本后再发布,使用灰度发布逐步切量
- 保留至少 N-1 版本以便快速回滚
七、故障排除
常见问题
模型调用 401 / invalid API key- 检查 API Key 是否正确(从 控制台 重新复制)
- 确认账户余额充足
- 检查 baseURL 是否为
https://api.gravitex.ai/v1(注意末尾/v1)
- 模型名称是否填写为 规范名(例如
gpt-5.5而非GPT-5.5) - “模型名称”与”API endpoint 中的模型名称”是否完全一致
- 优先选择 Flash / Mini 级别的模型
- 减少
max_tokens限制 - 启用 Dify 的结果缓存
性能优化参考
八、部署建议
生产环境(自建 Dify)Docker Compose 示例
安全配置
- 把 API Key 存入环境变量或 Secret Manager,不要硬编码在 Dify 应用配置里
- 启用 HTTPS,前置反向代理(Nginx / Caddy / Traefik)
- 为 Dify 后台启用 SSO / 双因子认证
- 定期更新基础镜像与依赖
健康检查
九、效果与对账
接入后回到 GravitexAI 控制台,可以看到调用量、token 消耗、费用分布、按模型的成功率等指标: